
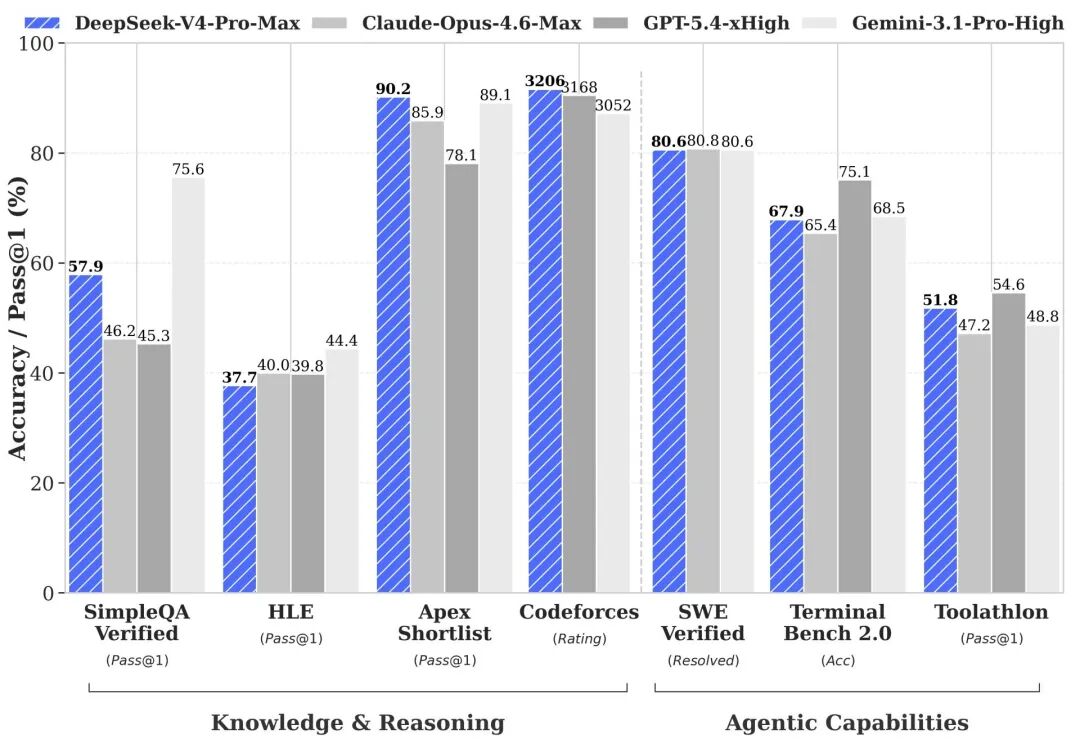
4 月 24 日,DeepSeek V4 系列的正式发布,引爆了全球 AI 行业:这款将百万 Token 超长上下文变为全系标配、性能比肩顶尖闭源模型的国产大模型,以 MIT 开源协议打破了高端大模型的技术垄断,被行业视为国产大模型从 “跟跑” 到 “并跑” 的标志性突破。
但兴奋之余,多数企业却卡在了落地门槛上:过去大模型的传统部署需要多节点集群支撑,硬件成本动辄数百万,部署周期长达数周,私有化需求一度望而却步。
如今,这一困境被彻底打破:依托红芯聚创™ HG9680 昇腾AI一体机,企业仅需单台设备,即可完成 DeepSeek-V4模型的部署,快速将顶尖大模型能力搬进企业内网。

本次部署的 DeepSeek-V4-Flash模型,是 DeepSeek V4 系列的更快捷高效版本,采用混合专家(MoE)架构:总参数量 2840 亿,单次推理仅激活 130 亿参数,在w8a8量化精度下,模型权重显存占用约280GB 级别,完美匹配单台 8 卡服务器的算力池。
根据数聚红芯内部部署测试验证,该量化版本可完美适配单节点 8 卡昇腾架构服务器,无需分布式集群组网。红芯聚创™ HG9680 昇腾910B AI一体机搭载 8 卡昇腾 910B NPU 模组,提供总计512GB 高速互联的HBM2e显存,不仅可完整承载模型权重,还预留出充足空间支撑百万 Token 上下文的 KV 缓存,完美匹配模型原生 1M 超长上下文能力。
部署完成后,该方案可实现:
低时延推理:昇腾原生适配下,请求推理延迟极低,能够满足企业内部问答、客服对话的实时响应需求;
长文本处理:支持一次性处理约 75 万字的超长文本,可直接承载企业全量代码库、合同文档的端到端分析,无需依赖复杂的 RAG 分片
自主可控:从鲲鹏处理器、昇腾 NPU 到 DeepSeek 国产大模型,全链路采用国产化技术栈,彻底摆脱海外算力生态依赖,满足金融、政务等领域的数据不出域合规要求。
相比于上一代DeepSeek V3.2 671B大模型,新一代V4模型搭配红芯聚创™ HG9680 昇腾910B AI一体机的解决方案,不仅将硬件采购成本降低 50% 以上,新模型还拥有着媲美世界顶级闭源模型的能力。
同时部署周期从数周压缩至 3 天内,企业无需配备专业的 AI 部署团队,即可快速完成模型的上线与调试。
数聚红芯专注于AI智能计算解决方案,以智能计算驱动产业数智化变革,针对 DeepSeek-V4 模型,能够为政企提供模型的私有化部署,确保数据完全不出内网,满足政府、智能制造、医疗、金融等各行各业的数据安全合规需求。同时通过自主研发的液冷技术大幅降低部署的能耗成本。
数聚红芯提供从硬件选型、集群搭建、应用开发到运维的全流程服务,政企单位无需投入专门的 AI 技术团队,即可实现 "开箱即用",DeepSeek-V4 解决方案的推出,将进一步助力全国的政企单位快速落地自主可控的顶级 AI 能力,加速数智化转型进程。